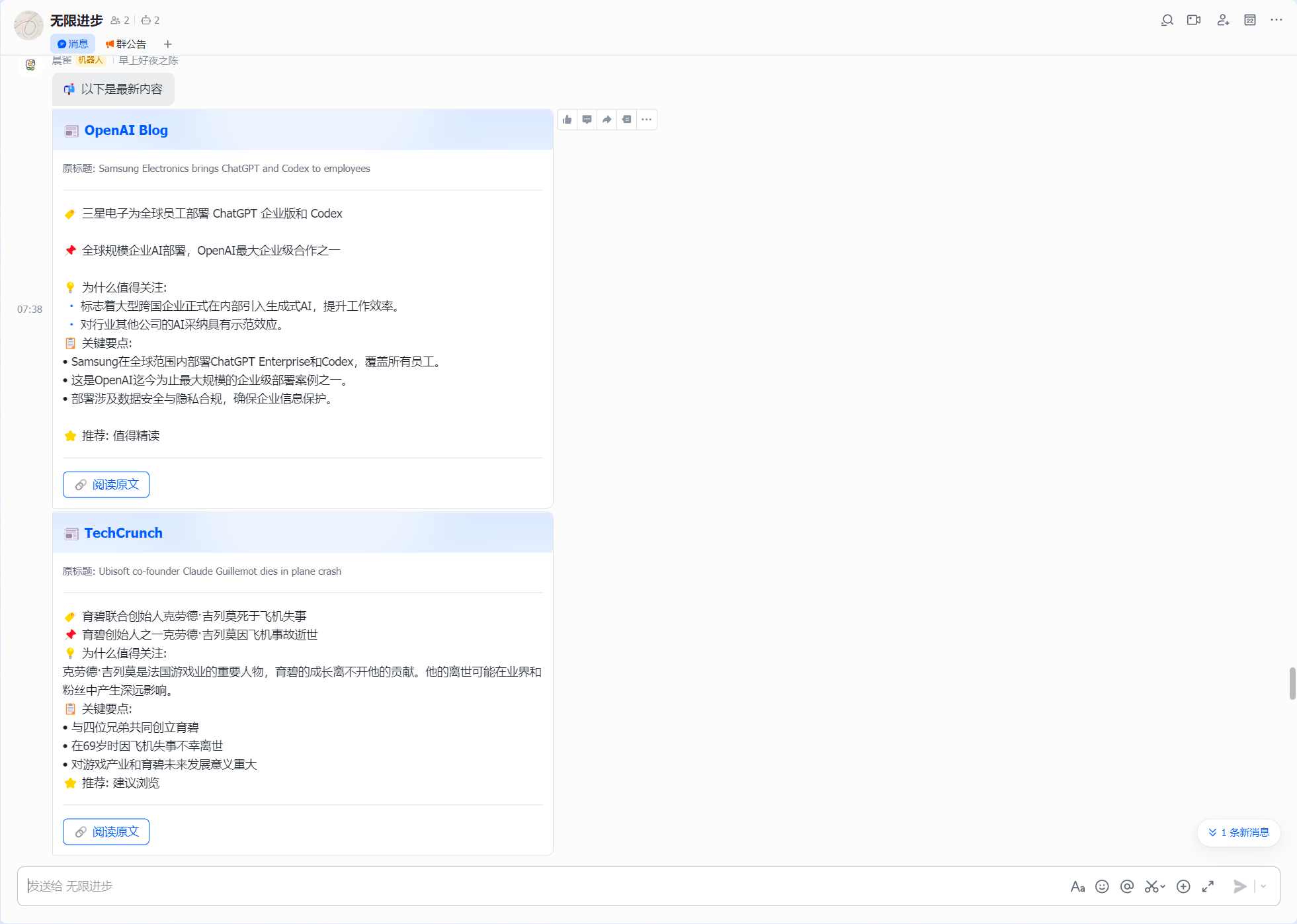
前阵子在openclaw的skill仓库里翻到一个叫rss-ai-reader的小工具,大致逻辑很简单:定时抓RSS订阅→丢给LLM生成中文摘要→推到飞书群里。开箱即用,看起来很美好,我直接部署。但用了几天,问题就冒出来了。
原版的问题
原版作者塞了91个RSS源在config.yaml里,都是技术博客,质量不低——SimonWillison、antirez、Gwern,每一个单独拎出来都值得订。但问题在于:抓取推送时,谁的文章多谁就占满推送队列。某天DaringFireball一口气发了5篇,我那天的推送列表小一半都是它。第二天Pluralistic又灌进来好几篇。我那几个真正想看的源——比如antirez偶尔冒一篇、DwarkeshPatel一周一篇——被稀释到看不见。你以为自己订了很多源,其实算法(或者说博客的生产频次)替你做了选择。高产源霸占了你的注意力,低产但高质量的源永远轮不到。
另一个问题是内容旱涝不均。有的时候一天更新了十几篇,有的时候三天推送不了一篇。原版一概而论,多的丢了不可惜,少的空转也不补充。
还有一个细节:原版虽然prompt里写了「把标题翻译成中文」「严格按以下格式输出」,但LLM经常不听话。有时候它输出英文标题,有时候标志符号漏了,有时候它直接说「我无法总结这篇文章」。没有任何校验,LLM做出什么就推什么。
我改了什么
我一口气改了一大堆,下面是所有改动的完整对比。
1.订阅模型:固定 + 随机的双轨制
原版的91个源全部硬编码在配置里。我拆成了两层:
- 固定订阅(5个):OpenAIBlog、AnthropicNews、TechCrunch、ArsTechnica、GitHubBlog。这些是核心关注,每轮必刷。
- 随机池(94个):单独一个
all_feeds.txt文件,涵盖SimonWillison、DwarkeshPatel、constructionp hysics、experimentalhistory等等。每次运行时从中随机抽20个源来抓取推送。
这样一来,每次推送既有必读的基本盘,又有随机刷新出来的「意外之喜」。第一次运行时推送给我的The just-say-no engineer was a ZIRP phenomenon(“说不”的工程师是ZIRP的现象),给了我全新的视野——程序员被裁员的一个可能原因,这要是在原版我估计永远不会收到它。
2.配额分配:轮询制,不让一个源刷屏
每轮最多推12篇,分配逻辑是这样的:
- 固定订阅先上,每个feed保底1篇,然后按feed轮询填充,上限8篇
- 固定没用完的配额溢出给随机
- 随机同样按feed轮询,上限4篇+固定未使用完的配额
核心思路是每个源不论产量高低,都有公平的曝光机会。TechCrunch一天出10篇,在我这也就占1-2个位置;GitHubBlog一个月写3篇,每篇都不会漏。
3.旱涝调节:pending队列
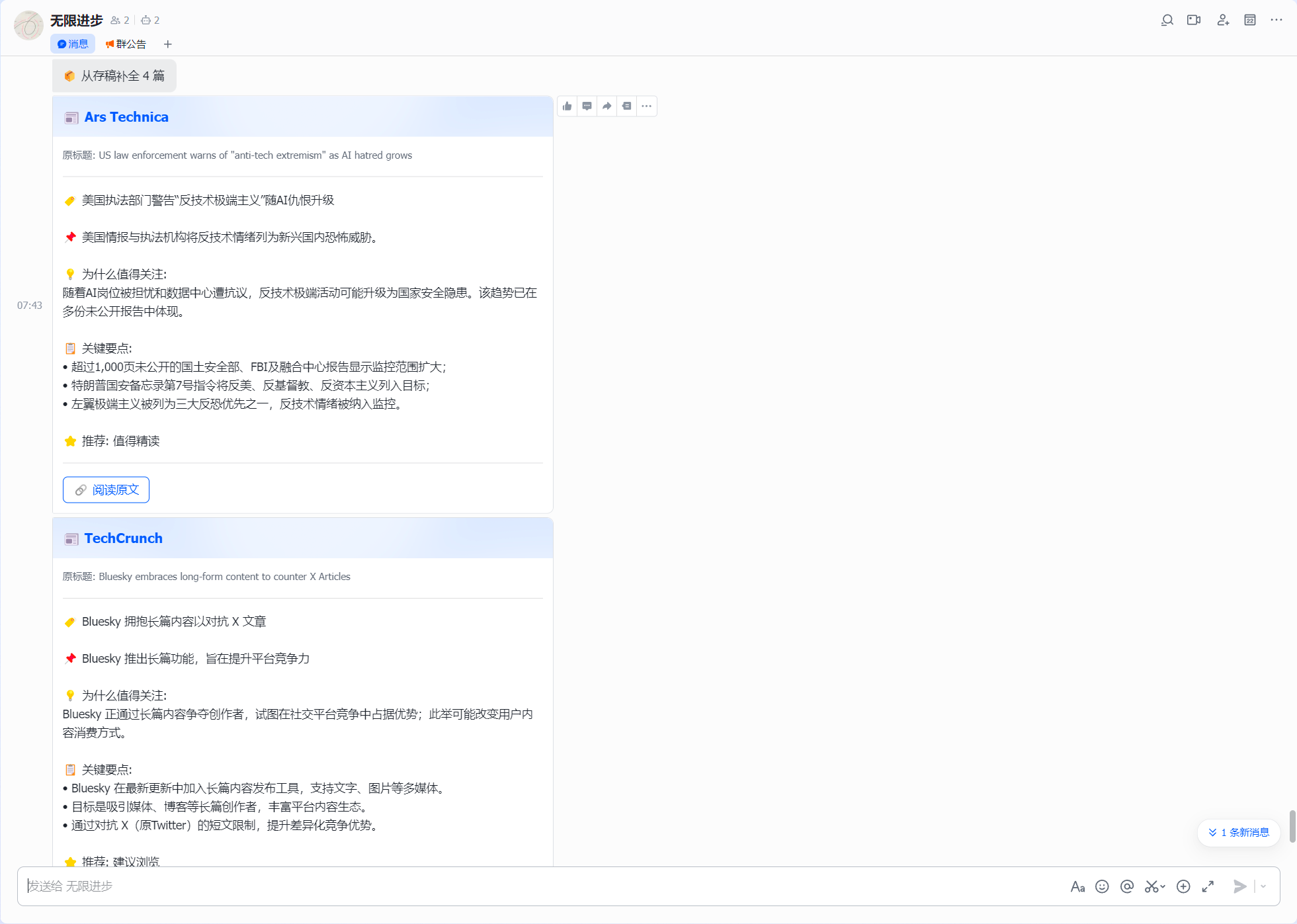
原版的做法是:新文章>max_articles,多的就丢掉不要了;新文章为0,就空转一轮。我加了一个pending队列。多出来的文章不进数据库标记为已处理,而是存下来等下一轮。如果下一轮新内容不足,自动从pending队列里补上来。把多的匀给少的。这招特别管用——在很多博客不更新的时候,新文章常常不足12篇,pending队列能补到满配。
4.翻译与审查机制:三层把关
这是比较核心的改动。原版prompt里写了翻译要求,但写归写,没人检查。
我加了三个关卡:
第一关:内容审查 _is_content_valid
很多RSSfeed摘取的内容是空的、只有链接、或者只有「Please enable JavaScript to view this page」。这些内容不值得浪费我的token,直接标记为已处理不进入队列。
第二关:摘要格式校验 _is_summary_valid
LLM输出摘要后,检查:
- 长度是否 ≥60字
- 是否以🏷️开头
- 五个标记(🏷️ 📌 💡 📋 ⭐)是否出现了至少3个
- 有没有出现「我无法总结」「I cannot provide」等拒绝回复
第三关:Reflection Retry
如果哪条不合格,不是直接丢弃,而是把具体原因反馈给LLM,告诉它:「你上次的问题是摘要过短/格式不完整/漏了标记,请按原始格式重写。」模型会根据反馈自我修正,最多重试2轮。
另外,我用过DeepSeek的模型,它有个现象——输出前先来一段<think>...</think>思维链。我写了个正则剥离器,把这些思考块从最终输出里清掉,保证推到飞书的只有最终摘要,没有LLM的内心独白。
5. LLM:从SDK到HTTP直连
原版用AnthropicSDK和OpenAISDK,每个都依赖一整个包。我换成了HTTP直连,支持DeepSeek和MiniMax。配置里填一个base_url+api_key就行了,只要有API密钥就能用。
6.并发与速度
原版是串行处理:N篇文章就调N次LLM,一次等一次。我加了ThreadPoolExecutor,默认3个worker并发跑摘要。12篇文章从1多分钟压缩到20秒左右。
7.飞书推送:主动节流
原版飞书推送没做任何限速。自定义机器人约5msg/sec的限频,连续推快了就返回code 11232。我加了1.2秒的最小间隔,遇到11232自动等2s→3s→5s指数退避重试。
8.日志:print() → logging
原版全程print(),跑完了控制台一关,什么痕迹都没有。我换成了logging模块,每次运行自动生成日志文件。还挂了全局异常钩子,万一哪个地方崩了,栈信息能写进日志文件,不会悄无声息。
9.数据库扩展
原版数据库只有去重功能。我加了category、pushed、content三个字段,新增了store_pending、get_pending_articles、mark_pushed三个方法,支撑pending队列。
10.其他
- Telegram支持被我移除了——我没在用
- Python版本降到了3.6.8兼容——服务器上的Python比较老
效果
改动落地后跑了一段时间,飞书群里的画风变了:
- 信息源不再被高产源绑架,固定关注必读,随机池拓宽视野
- 新内容少了也不会空转,pending队列自动补位
- 推送到手机上的每一条都过了质检,没有「请启用 JS」的垃圾,没有格式乱七八糟的半成品
- 每天总有一两篇是「意外刷到的惊喜」,比如 Don't call yourself a Software Engineer, and other Career Advice 讲 ai 背景下工程师应怎么做,以及 StubZero: $148,337 RCE in Google Cloud Production 讲安全漏洞。
代码
原版作品:
- rss-reader — 轻量级的 RSS AI 阅读器
本人作品:
- rss-ai-reader — RSS 摘要推送工具
评论
游客无需注册即可评论。
你提交的昵称、邮箱、网址和评论内容会保存在服务端,用于展示评论身份、接收回复及必要的安全审计。
浏览器会本地保存已填游客信息和评论草稿,方便下次免填。
回复提醒会通过站内消息和邮件通知。