出于想要openclaw帮我查找论文以及每日推送的想法,我在openclaw的仓库以及GitHub中折腾了很久,找到几个可以直接使用的项目、skill,但是实际上使用的体验不符合预期,加上想自己动手做点东西,所以我基于 findpapers(Jonatas Grosman的开源项目)和自己重构过的RSS推送工具做了一个。
我遇到的问题
我使用到的:
1.Daily Paper Digest 使用的平台是arXiv和HuggingFace(国内不可用)。关注的时间点是每一天,可以关注多个细分领域。
2.paper-recommendation 使用的平台是arXiv。它也可以日常推送,但是更多的是关注一个大领域近期的论文,经过一套评估流程后生成简介。
问题:
1.它们两个和rss-ai-reader一样,对推送摘要格式有要求,但是对结果没有审查,格式与内容常常波动;
2.获取信息的渠道单一,都有局限性,无法获得高质量论文;
3.时间跨度不够,只关注近期的内容,无法查询到过去几年的文章;
4.paper-recommendation,在想要找到新的论文时,让ai自行探索,最后获得的内容只是贴近想要的,不精确。
5.paper-recommendation的评估流程对我来说有些臃肿、浪费,我只需要了解大致的内容,然后我自己去看、去思考;
6.Daily Paper Digest只推送当天更新的论文,
改进后的技术逻辑
针对上面遇到的问题,我逐一对应解决:
1.三层验证机制
原版prompt写了格式要求但没人检查。我加了三个关卡:
-
第一关
_is_content_valid:过滤空内容、只有链接、"Please enable JavaScript" 等垃圾,不配浪费 token -
第二关
_is_summary_valid:长度 ≥60 字、🏷️📌💡📋⭐ 至少出现 3 个、没有"我无法总结"等拒绝回复 -
第三关 Reflection Retry:不合格时把具体原因告诉 LLM 让它重写,最多 2 轮
2.findpapers多库搜索
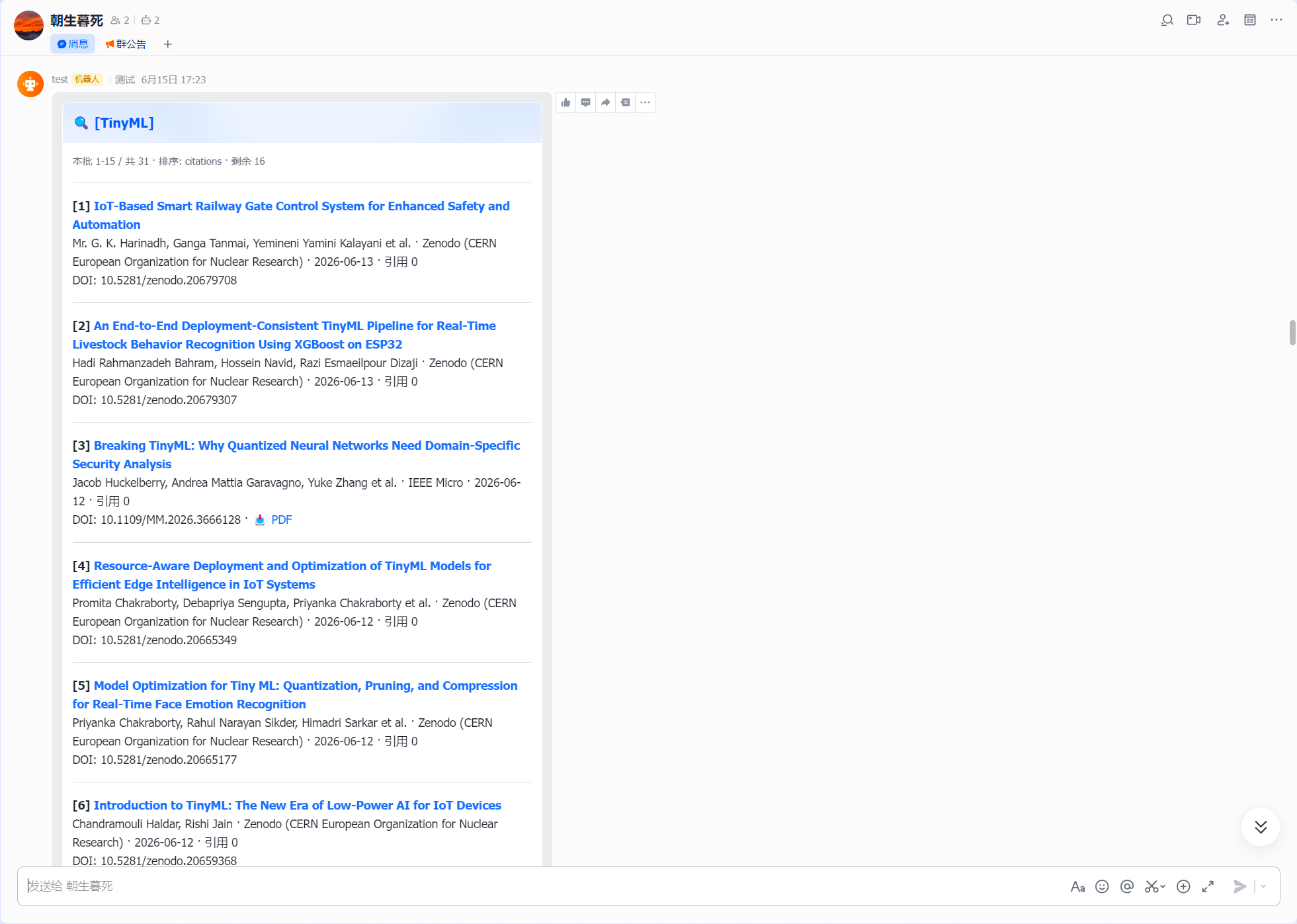
findpapers包装了arXiv、OpenAlex、Semantic Scholar、PubMed、IEEE等7个学术搜索引擎(我实际只开了arXiv和OpenAlex),一套DSL自动翻译到各家的原生查询语法。
3. --search 自定义时间窗
定时推送默认只查 7 天内的新论文。但临时查询模式 --search 支持 --since YYYY-MM-DD 和 --sort citations,可以一次性拉几年范围、按引用量排序挖经典,解决了"查不到旧文章"的问题。
4.写死 query + 简化链路
- config.yaml每条query是精确DSL,不让AI发散什么"相关方向",搜什么完全可控
- 去掉paper-recommendation复杂的评估流程,简化到:搜索→去重→AI摘要→推送,三步走完。
5.pending队列
当天多出来的不进数据库标记为已处理,而是存下来等下一轮。如果下一轮新内容不足,自动从pending队列里补上来,把多的匀给少的。
整体链路
config.yaml 配 N 条 query → findpapers 搜 7 个库 → 去重 → 配额分配 → DeepSeek 摘要 → 飞书卡片
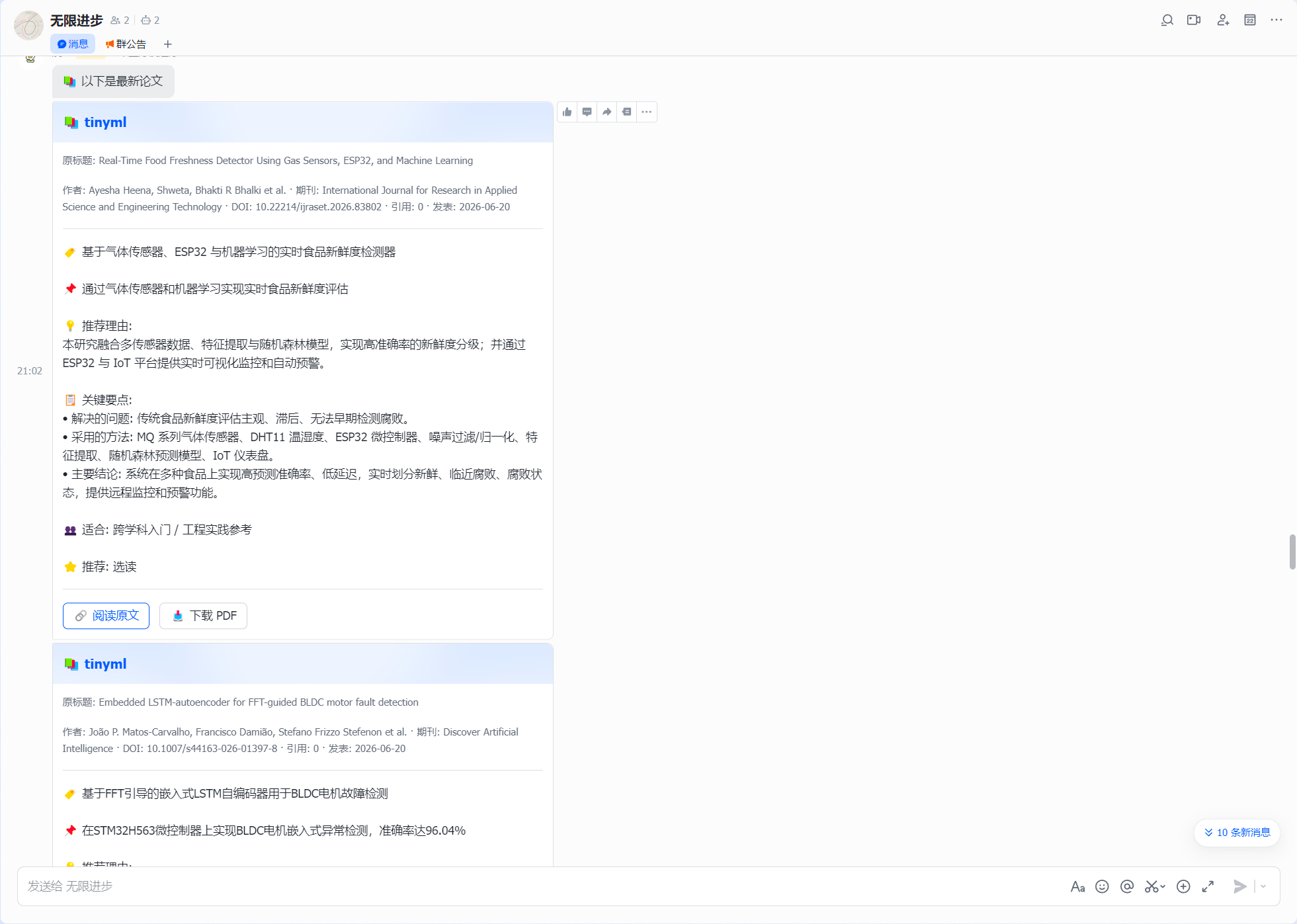
推送逻辑、待推送队列、内容审查机制都直接复用了之前在rss-ai-reader写的。每轮最多8篇,按分组配额轮询分配,获取的多了进pending队列下次补出。每篇论文用AI生成结构化中文摘要——标题翻译、一句话贡献、推荐理由、关键要点、适合谁读——然后推一张飞书卡片,带原文链接和PDF下载按钮。
另外还做了一个对话式查询:想知道某个方向最近有什么论文,直接和openclaw说关键字,结果会以列表卡片的形式推送到飞书。在列表里看到感兴趣的,挑几篇告诉openclaw,然后就会为每篇生成摘要再推过来。类似"搜一下→看看→细读"的两步式体验。
实际效果
老实说,跑了一段时间,在查询质量上和直接让openclaw调用OpenAlex查差别不大,甚至不如。让openclaw使用paper-push的查询可以找到论文,不过目前只能使用arXiv,而OpenAlex不稳定,剩下的需要有企业邮箱或者教育邮箱才可以申请,我没有使用到。而让openclaw直接调用OpenAlex,只要连通就可以获得不错的论文,因为可以根据引用量来排序。就我做出的查询效果而言,比不上在知网、谷歌学术直接查询,有很大的改善空间。不过话说回来,虽然它查询的效果不符预期,但是在推送上面,比openclaw仓库上的skill还是强上一些,把我遇到的问题基本解决好了。
未来可期
我做出来的也存在不少问题——库看似被拓展了实际上并没有,稳定的只有arXiv,以及在小服务器上使用查询并不流畅,底层搜索库占用的内存较多,容易触发限制。针对这两个问题,我还在探索中,目前考虑的计划:构建中转服务器并重构底层搜索库,这样应该解决网络限制和内存占用高的问题。
代码
底层搜索库:
- findpapers(Jonatas Grosman的开源项目)
本人作品:
-
rss-ai-reader — RSS 摘要推送工具
-
Paper-push — 论文搜索摘要推送工具
评论
游客无需注册即可评论。
你提交的昵称、邮箱、网址和评论内容会保存在服务端,用于展示评论身份、接收回复及必要的安全审计。
浏览器会本地保存已填游客信息和评论草稿,方便下次免填。
回复提醒会通过站内消息和邮件通知。